How to View the First N Rows in a Pandas Data Frame
When working with huge datasets, it is often helpful to review the first few rows of the data rapidly in order to get a concept of what the data looks like. There are three straightforward ways available in Pandas for accomplishing this goal: the head approach, slicing, and indexing. In this article, we will discuss each of these approaches in further depth and present examples to assist you in getting started with them. When it comes to investigating and cleansing your data, these methods will be of great use to you, regardless of whether you are a novice or an experienced data analyst. So, let’s dive in!
3 Ways to View The First N Rows in a Pandas Data Frame
Head Function
The head function will allow you to quickly see the first N rows of data in a pandas data frame. By defualt this function will return the first 5 rows of your data. However the Head Method: df.head(N) where N is an integer that specifies the number of rows to return from the beginning of the data frame
# import the Pandas with the import function and save it as a variable.
import pandas as pd
# where is the data
path = "https://raw.githubusercontent.com/Gaelim/youtube/master/HR_file.csv"
# Using the pandas variable and the read_csv function
df = pd.read_csv(path)
#Use the head function to take peak at the first 10 rows of the data
df.head()

Slicing to View the First N Rows of Data
Pandas has a way to get to a subset of the rows in a data frame called “slicing.” This can be done by using square brackets and the colon (:) operator to specify a range of rows. You can choose the range of rows by giving the start and end indices of the rows you want, or you can just give the start or end index and leave the other one blank. In that case, the default will be the beginning or end of the data frame, depending on which one you left blank.
For example, df[:5] returns the first 5 rows of the data frame df, while df[3:10] returns the rows with indices 3 through 9 in the data frame. Using slicing in Pandas is a quick and easy way to get to and look at a part of your data.
# Import the Pandas library.
import pandas as pd
# Find the data location
path = "https://raw.githubusercontent.com/Gaelim/youtube/master/HR_file.csv"
# Read in the data
df = pd.read_csv(path)
# Let's slice the data to view the first 5 rows of the data
df[:5]

Indexing to View the First N Rows of Data in Pandas
Indexing in Pandas means choosing rows or columns from a Pandas data frame based on how they are labeled or where they are. Pandas has a number of ways to index data, such as the.loc and.iloc attributes.
.loc indexing is used to pick out data based on how the rows and columns are named. For example, df.loc[row label, col label] returns the value in the specified row and column, where row label and col label are the names of the desired row and column, respectively.
.iloc indexing, on the other hand, picks data based on where the rows and columns are in terms of integers. For example, df.iloc[row index, col index] returns the value in the given row and column, where row index and col index are the integer positions of the desired row and column, respectively.
Indexing in Pandas is a powerful way to find and change specific parts of your data, and it is a key part of the process of cleaning and analyzing data. In this example, we will use the iloc method. However in this example, you can also use the df.loc method.
# Import the Pandas library.
import pandas as pd
# Identify the data location
path = "https://raw.githubusercontent.com/Gaelim/youtube/master/HR_file.csv"
# Read in the data
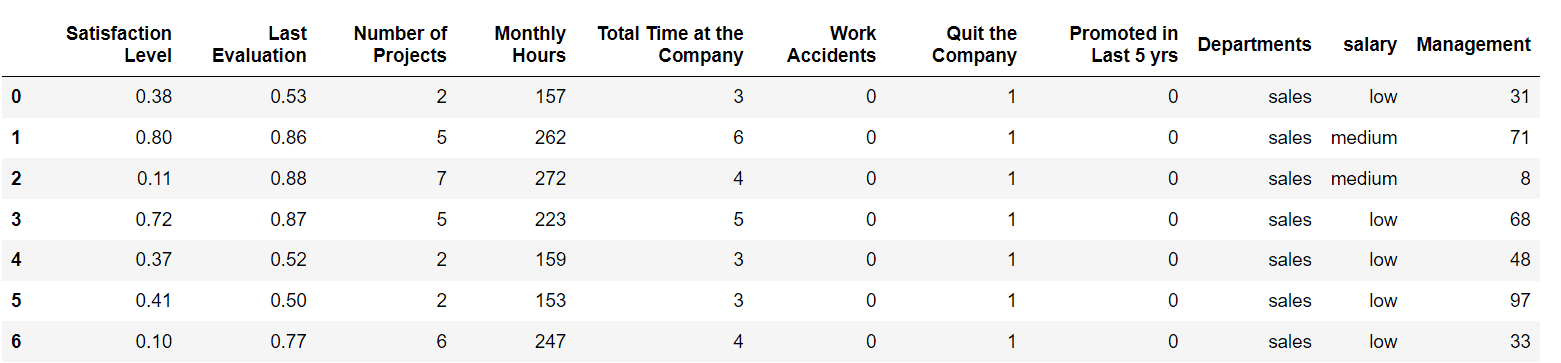
df = pd.read_csv(path)
# Let's slice the data to view the first 15 rows of the data
df.iloc[:7]